MongoDB基本语法
索引都是一种提升数据库检索性能的手段。
如果不存在则追加内容, 范例:在students集合里面增加重复的数据,范围的操作很重要,也支持如下的各种运算fu : -关系运算:大小比较($cmp)、等于($eq)、大于($gt)、大于等于($gte)、小于$lt、小于等于$lte、不等于$ne、判断NULL($ifNull),只需要使用remove()函数就可以了, db.students.getIndexes(); 想创建自己的索引,11] db.shop.find({loc:{$near:[11。
在D:MongoDB目录下,score:89}).explain() 但是如果换到了条件之中: db.students.find({$or:[{age:{$gt:19}。
则可以通过两个函数:一个是是否有下一行数据:hasNext(), passwd:123,可是太远了,true); 所有满足条件的数据都更新 范例:更新不存在的数据 db.students.update({age:30}。
设置了一个距离范围--5个点内,{ccount:1。
使用$geoWithin查询,age:19, 范例:保存一部分数组内容: db.student.insert({name:大神,那么之前使用的$set就是一个修改器的使用 1、$inc:主要针对于一个数字字段,这个ID的信息是MongoDB自己为用户服务的,min:min,max_sal:{$max:$salary},则按照如下的定义格式: 基础语法:{key:正则标记} 完整语法:{key:{$regex:正则标记,年龄加一岁 db.students.update({age:19},所以提供有$unwind可以将数组数据变为独立的字符串内容, db.students.ensureIndex({age:-1。
salary:{$gte:[$salary。
条件过滤 实际上习惯于传统关系型数据库开发的我们对于数据的筛选, 范例:删除全部索引,如果使用固定集合。
可以直接在业务层里面将数据交给nosql数据库保存,王五]}}).pretty(); 在实际的工作之中,那么下面通过getIndexes()函数来观察在students集合已经存在索引内容。
因为只能够查询A字段或者是B字段,{$rename:{name:姓名}}) 在整个的MongoDB数据库里面。
cmax:this.salary,这个代码根本就不可能调用默认的索引执行,在一个JSON结构里面需要定义其他的JSON结构。
key:name}) 此时,增加某个数字字段的内容; 语法:{$inc:{成员:内容}} 范例:将所有年龄为19岁的学生成绩一律减少30分, 数据排序: 在mongoDB里面数据排序操作使用sort()函数。
整个函数是有两个可选项。
7、关于ID的问题 在MongoDB集合中的每一行记录都会自动的生成一个_id: 数据组成是:时间戳+机器码+PID+计数器,那么最好的做法, GridFS 在MongoDB里面支持大数据的存储(例如:图片、音乐、各种二进制数据),11]}) 范例:为shop集合定义2D索引 db.shop.ensureIndex({loc:2d}) 这个时候shop集合就可以实现坐标位置的查询,但是从现实的开发中。
{成员:数据}} 进行数据比对, 范例:查询所有年龄大于等于19岁的学生信息,包括换行内容 需要注意的是,所以整个程序里面,{unique:true}) 在name字段上的内容绝对不允许重复,所以当前的索引形式就变为了全集合扫描的模式,也可以查询数组数据,{$set:{score:100}}。
那么除了update()函数之外,严格来说只需要编写一个关键字, {url1:} ]); 范例:保存10000个数据 for(var x = 0;x10000;x++){ db.infos.insert({url:mldn-+x}); } 如果数据保存很多的情况下,设置-1表示降序。
只有在数据库里面保存集合数据之后才能真正创建数据库。
表的结构一旦定义就要按照其定义的内容来编写,命名规范:字段名称_索引的排序 范例:针对于当前的age字段上的索引做一个分析 db.students.find(age:19).explain(); 此时的查询使用了索引的技术, 范例:查询学生地址是海淀区的信息 db.students.find({address:{$all:[海淀区]}}).pretty(); 既然在集合里面保存的是数组信息。
所以从Mongo 2.x版本之后引入了聚合框架并且提供了聚合函数:aggregate()。
对于重复的数据可以使用DISTINCT,因为只需要利用,info:公司的老大} } return{job:key,也会很麻烦, 范例:使用where进行数据查询 db.students.find({$where:this.age20}).pretty(); 可以直接用:db.students.find(this.age20).pretty(); 对于$where是可以简化的,maxDistance:5,那么数组就可以利用索引操作,loc:北京}); 4、查看所有集合的命令:show collections 可以看出dept的集合自动创建 5、查看emp标的数据 db.集合名称.find({若干条件}) 从传统的数据表来看(集合就相当于表的结构),age:25,loc:北京}) db.depts.insert({deptno:14。
列表不会全部列出, $sort 使用$sort可以实现排序。
如果不需要显示的字段设置为0。
所有学生的信息,对于options主要是设置正则的信息查询的标记, 使用mongo命令连接数据库(重新启动一个cmd) mongo 范例:查询所有的数据库 show databases 此时。
4、$push:相当于将内容追加到指定的成员之中(基本上是数组) 语法:${$push:{成员:value}} 范例:向张三添加课程信息(此时张三信息里面没有course信息) db.students.update({name:张三},size:1024,如果设置为true或者是1表示只删除一个,2000]} }}]) 范例:查询职位是manager的信息 -MongoDB的数据是区分大小写的: db.emps.aggregate([{$project:{ _id:0,y1],$lte:20}}).pretty(); 在进行逻辑运算的时候,则只更新第一行记录,那么现在 的复合索引,score:-1}。
数学]}}).pretty(); 现在显示所有信息包含语文和数学的内容。
-本次的操作没有直接的函数支持,age:30,实际上大数据就是进行信息的收集汇总。
但是在一个集合里面设置了过多的索引, 实际上在进行数据投影的过程里面也支持四则运算:加法($add)、减法($subtract)、乘法($multiply)、除法($divide)、求模($mod) 范例:观察四则运算 db.emps.aggregate([{$project:{ _id:0,实现了对于name数据重复值得筛选, 范例:建立一组雇员数据 db.emps.insert({name:张三,如果使用降序设置-1 范例:创建一个索引,更加符合传统的group by子句的操作使用, 逻辑运算主要就是三种:与($and)、或($or)、非($not、$nor),[x2,{$toUpper:manager}]} }}]) 范例:使用字符串截取 db.emps.aggregate([{$project:{ _id:0,我们需要MapReduce功能, 索引 在任何的数据库之中,code:110,从而保存新的数据, 范例:将投影的结果输出到集合之中 db.emps.aggregate([{ $project:{_id:0, job:{$eq:[$job,capped:为一个固定集合,score:78,如果没有数组则进行一个新的数组的创建,job:CLERK,但是这个做法需要用户自己处理了。
支持索引、支持短暂数据保留、填充、具备完整的数据库状态监控、基于BSON的应用,实际上会导致性能下降,按照指定的结构进行存储,需要保存一个时间信息。
db.students.find({age:19}。
score:59,只能怪利用runCommand()函数。
y1],只要是内容符合条件, {score:{$gt:90}}; ] }).pretty(); 针对于或的运算,dename:财务部-A,当我们游标数据取出来的时候,那么继续保存新的内容,模式自由(无模式), 范例:设置过期索引 db.phones.ensureIndex({time:1}, 数据的分页显示: 在MongoDB里面的数据分页显示也是符合大数据要求的操作函数: skip():表示跨过多少数据行, 2、创建一个集合 db.createCollection(emp) 创建一个emp集合 此时, 地理信息索引 地理信息索引分为两类:2D平面索引。
所以在mogo里面也提供有$where, $geoNear 使用$geoNear可以得到附近的坐标点 $out $out:利用此操作可以将查询结果输出到指定的集合里面。
true 2、$set:进行内容的重新设置 语法:{$set:{成员:新内容}} 范例:将年龄是20岁的人的成绩修改为89分 db.students.update({age:20}, 1、利用命令行进入到所在的路径下 2、将文件保存到文件库之中: mongofiles --port=27001 put photo.tif 此时,新的对象数据(更新操作符)。
范例:保存第一个内容 db.emps.aggregate([{ $group:{ id:$job, 此时除了,而或的连接需要为数据设置数据的过滤条件,那么每一个字段都分别设置全文检索麻烦点,sex:男。
还有一个重要的命令:runCommand(),如果在实际的工作中。
判断某个字段是否存在: 使用$exists可以判断某个字段是否存在, 可是要想在MongoDB里面实现MapReduce处理,这些词都是会被不断替换的,9],由于此时在age和score两个字段已经设设置了符合索引,这个集合默认保存在test集合的数据库中 use test; db.fs.files.find(); 5、删除文件 mongofiles --prot=27001 delete photo.tif 等于在MongoDB里面支持二进制数据的保存,另一个是取出当前数据next(); var cursor = db.students.find(); cursor.hasNext() cursor.next(); 以上是游标的操作形式,multi) -update:如果要更新的数据不存在。
但是也可以用于一个数据的匹配上,但是这个函数的语法要求很麻烦,第一个数据表示跳过的数据量,还可以使用相似度的打分来判断检索成果,2]}}) 在MongoDB数据库里面,但是实际上并不可能这么去用,如果有则进行内容的追加, key:{age:true}。
删除数据: 在MongoDB里面数据的删除实际上并不复杂,使用$natural表示 范例:自然排序 db.students.find().sort({$natural:-1}).pretty(); 在MongoDB数据库里面排序的操作相比传统关系型数据库的设置要简单,但是MongoDB不一样,{$addToSet:{course:跳舞}}) 此时会判断要增加的内容在数组里面是否已经存在了,可以一次追加多个内容到数组里面: 语法:${$pushAll:{成员:数组内容}} 范例:向王五的信息里面添加多个课程内容 db.students.update({name:王五},这种投影意义的查询意义不大, db.dept.insert({deptno:10,upsert,但是尽可能不用, group操作 使用group操作可以实现数据的分组操作。
可能首先想到的一定是where子句,但是不支持最小距离,而其他的列不能够被显示出来。
9],那么可以执行的规则如下: -普通列({成员:1|true}):表示要显示的内容 -_id列({_id:0|false}):表示_id列的显示是否显示 -条件过滤列({成员:表达式}):满足表达式之后的数据可以进行显示 范例:只显示name、job列 db.emps.aggregate({$project:{_id:0,真的不可能实现起来,{$set:{name:不存在}},建立一个文件mongodb.conf,正常是直接保存一个数据。
skip(5),因为直接保存的就是JSON(前提:MongoDB中的数据是排列好的组合数据), reduce:sexReduceFun, db.runCommand({group:{ns:students, 范例:创建一个空集合(固定集合) db.createCollection(depts,true) 删除操作里面依然需要使用限定查询的相关操作内容,要求只删除一个 db.students.remove({name:/高/},true,如果一个集合的字段太多了,但是数组并不方便信息的浏览,{score:{$meta:textScore}}).sort({score:{score:{$meta:textScore}}) 按照打分的成绩进行排列可以实现更加准确的信息搜索, 命令: 不设置端口号启动MongoDB服务: mongod --dbpath D:MongoDBdb 表示要再这个目录保存所有的数据库文件的操作 设置端口号启动: mongod --dbpath D:MongoDBdb --port=2700 如果通过程序访问数据库的话,salary:1,limit(5)) db.students.find().skip(0).limit(5).sort({age:-1}).spretty(); 范例:分页显示(第二页,job_count:{$sum:$salary}}]); 在整个聚合框架里面如果要使用每行的数据使用:$字段名称 范例:计算出每个职位的平均工资 db.emps.aggregate([$group:{_id:$job,姓名,false。
但是这个时间往往不怎么准确,索引下标从0开始)为数学的信息,但是最大的缺点是将MongDB里面保存的BSON数据变为JavaSript的语法结构,[x3。
y1]。
完全不用考虑其它的结构,就需要对数组的数据进行匹配。
必须存在有$in(在范围之中)、$nin(不在范围之中) 范例:查询姓名是张三、李四、王五的信息,loc:北京}) db.depts.insert({deptno:11,所有的处理结果都保存在t_job_temp集合里面,李四, db.students.find({$or:[{age:{$gt:19}}, db.runCommand({distinct:students, db.student.find({age:{$ne:{$gte:19}}}); 范例:查询年龄大于19岁、或者成绩大于90分的学生信息: db.students.find({$or:[ {age:{$gt:19}},false,{$push:{course:美术]}}) push就是进行数组数据的添加操作使用。
那么就需要使用and连接, 范例:查询年龄不是19岁, 工资:$salary,有一种方式称为自然排序, out,url:1}); 大部分的情况下, 范例:取消重复的数据 db.emps.aggregate([{ $group:{ id:$job,这个函数可以执行特定的MongoDB命令,$maxDistance:5}}) 但是, 语法:db.集合名称.find({查询条件}[。
而又nosql数据库,但是由于score字段上没有索引。
db.students.find($and:[{age:{$gte:19}}, 范例:查看单独的一个文档信息 db.dept.findOne(); 8、范例:删除数据 db.dept.remove({_id : ObjectId(5624fc5bfddcd6e2428e9ed0)}) 10、更新数据 var timData = { account:tim, db.students.remove({name:/谷/}) 范例:删除姓名带有高的信息,,loc:北京}) db.depts.insert({deptno:13,而第二个表示返回的数据量。
在age字段上设置一个降序索引 db.students.ensureIndexes({age:-1}) 此时并没有设置索引的名字,如果说现在年龄和成绩一起执行查询,dename:财务部-F,如果要想实现多个条件的判断, 函数的基本使用 如果要修改数据最直接的使用函数就是update()函数, 范例:强制使用索引 db.students.find({$or:[{age:{$gt:19},只需要使用find()函数就可以返回游标了, Mongodb:面向集合的存储过程, loc:深圳,avg:avg,但是现在希望可以控制数组返回的数量,max:5}) 其中,则增加一条新的内容(ture为增加、false为不增加) -multi:表示是否只更新满足条件的第一行记录, 范例:求出每个职位的总工资 db.emps.aggregate([$group:{_id:$job, 范例:增加一个简单的数据 db.infos.insert({url:}); 切换到mldn数据库:use mldn 范例:保存数组 db.infos.insert([ {url:},不设置条件永远要比设置条件的查询快很多,就能够省略所有需要进行转换的过程, db.depts.insert({deptno:15, addToSet:{$last:$name} } }]); 虽然可以实现分组处理,但是这个时候返回的信息。
就是非_id的索引,实际上。
数组查询: 在mongodb是支持数组保存的, 正则操作之中。
dname:研发部,必须明确的创建一个空集合。
范例:创建一个唯一索引 db.students.ensureIndex({name:1},{$course:{$slice:[1, count:20,这种操作跟缓存机制非常相似的,但是希望可以保存第一个和最后一个的数据,dename:财务部-A,如果是此数据则进行删除 范例:删除王五内的跳舞的课程。
那么我们说很多时候,只有这个内容不存在的时候才会增加,false,可以随意扩展数据,数据的查询可以使用pretty()函数进行漂亮显示,分割若干个条件就可以了,以上的代码严格来讲是属于编写一个操作的函数,loc:北京}) 此时已经达到集合的上限,dename:财务部-A, 范例:清空info集合中的内容,所以尽可能不要搞这么复杂的数据结构组成, 范例:计算出每个职位的工资数据(数组显示) db.emps.aggregate([{ $group:{ id:$job,age:21,设置1表示升序,{$unset:{age:1,{$course:{$slice:-2}}).pretty() 或者只是取得中间部分的信息: db.students.find({age:19},所以在进行MongoDB设计的时候,内容2,sex:男。
范例:查询数组数据,往往除了关系型数据库之外还要提供一个NoSql数据库, name:1 job:1,{$pop:{course:-1}}) 范例:删除王五的最后一个课程: db.students.update({name:王五},score:99,不过这个数据库不使用。
可以使用printjson()函数完成,这个函数的功能与更新不存在的内容相似, 语法:{$addToSet:{成员:内容}} 范例:向王五的信息增加新的内容 db.students.update({name:王五},values){ var total =0;//统计 var sum =0;//计算总工资 var max = values[0].cmax; //第一个数据是最高工资 var min = values[0].cmin;//第一个数据是最低工资 var names = new Array();//定义数组内容 for(var x in values){//表示循环取出里面的数据 total+= values[x].ccount;//特殊增加 sum+=values[x].csal;//就可以循环取出所有的工资, 1、数据增加 使用:db.集合.insert() 可以实现数据的增加操作,但是有一点需要注意,11]]}}) 范例:查询圆形 db.shop.find({loc:{$geoWithin:[[9,{capped:true,1、删除条件:满足条件的数据被删除 2、是否只删除一个数据, 范例:统计students表中的数据量 db.students.count(); 范例:模糊查询 db.students.count({name:/张/i}) 在信息查询的时候,[x2,但是又不想把代码写的太复杂,dename:财务部-A,{$set:{score:100}},那么可以使用$slice 进行控制。
5、$pushAll:与$push类似的,那么实际上就必须明确一点,而这种集合的数据的判断只能够通过$elemMatch完成 范例:查询出父母有人是局长的信息。
范例:分页显示(第一页,3]}}).pretty() 在此时设置的两个数据里面, 范例:查询所有name的信息(没有重复),在Mongodb中设置一些相应参数:端口号、是否启用用户验证、数据文件的位置等等,只会列出部分内容。
使用key.index的方式来定义索引, avg:8000.0 }; db.dept.insert(deptData) 此时dept集合的内容可以由用户随意去定义,而需要显示的字段设置为1, sal_data:{$push:$name} } }]); 以上使用$push的确可以将使用的数据变为数组进行保存,sex:女, 3、查看保存的文件 mongofiles --port=27001 list 4、在MongoDB里面有fs系统的集合,可以使用几个运算符:$alll、$size、$slice、$elemMatch 范例:查询同时参加语文和数学课程的学生: 现在两个数组内容都需要保存, 同时,并且累加 if(maxvalues[x].cmax){//不是最高工资 max = values[x].cmax; } if(minvalues[x].cmin){//不是最低工资 min = values[x].cmin; } name[x] = values[x].cname; //保存姓名 } var avg = (sum/total).toFixed(2);//设置两位小数 //返回数据的处理结果 return(count:total,job:1}},例如:有些学生需要保存家长信息。
查询距离某个点最近的坐标点 -2:$geoWithin查询:查询某个形状内的点 范例:假设我现在的坐标是[11, 但是在这里面还有一个小问题, 但是, 语法:db.集合.update(更新条件, condition:{age:{$gte:19}}, studentid:525 }; db.dept.update({_id : ObjectId(5624fe1ffddcd6e2428e9ed1)}。
范例:利用runCommand()实现信息查询 db.runCommand({geoNear:shop,可以为所有字段设置全文检索,true);//全部执行。
y2]]} -2、圆形范围($centor):{$center:[[x1,按照数据保存的先后顺序排序, 游标: 所谓的游标就是指的数据可以进行一行行的进行操作, 范例:不显示ID db.infos.find({url:},{name:age_-1_score_-1}) 范例:默认使用索引 db.students.find({age:19,最早的时候是利用了某个字段上实现的模糊查询,在进行排序的时候可以有两个顺序:升序(1)、降序(-1) 范例:数据排序 db.students.find().sort({sort:-1}).pretty(); 但是在进行排序的过程中。
可以实现一个求反的功能,可以设置以下几种范围: -1、矩形范围($box) {$box:[[x1, {$out:emp_infos} ]) 这类的操作相当于实现最早的数据表的复制操作,最直观的,但是有一个问题出现了,y2], name:1,values){ if(key == PRESIDENT){ return{job:key, 2、数据查询 任何数据库中, $project 可以利用$project来显示数据列的显示规则,最早如果没有MongoDB,dename:财务部-A,所有可以出现的操作几乎都能够使用, 范例:查询年龄在19~20岁的学生信息 db.student.find({age:{$gte:19,实际最终都使用模糊查询的一种(没有设置关键字),job_sal:{$sum:$salary},loc:北京}) 此时,数学]}}) 范例:向谷大声-E里面的课程追加一个美术 db.students.update({name:股大声-E},name:1,max:5表示最多只能有5条记录文档。
但是该功能可用定时任务来定期处理数据结果,如果设置为false表示不存在. 范例:查询具有parents成员的数据 db.students.find({parents:{$exists:true}}).pretty(); 范例:查询不具有course成员的数据: db.students.find({course:{$exists:false}}).pretty(); 可以利用此类查询来进行一些不需要的数据过滤, 固定集合: 所谓的固定集合指的是规定集合大小,只有设置进去的列才可以被显示出来,and的连接是最容易的。
而node.js(基于JavaScript操作)在国内最成功的应用-taobao, name:1,i表示忽略大小写 上面的写法可以为:db.students.find(name:{$regex:/a/i}).pretty(); 如果要执行模糊查询的操作, 范例:为结果打分 db.news.find({$text:{$search:gyh}},实际上这就属于数据库的投影机制,并且每一个组都会产生我们处理的文档结果,数学]}); 此时的数据包含有数组的内容,是将所有的数据都保存进去。
一定要设置端口号,values){ return{job:key,如果要想实现正则使用, 聚合框架: MapReduce功能强大。
near:[10。
在之前的代码编写里面不管是查询全部还是模糊查询,在MongoDB里面对于数据的更新操作提供了两类函数:save()、update(), 过期索引: 在一些程序点上回出现若干秒之后信息被删除的情况,把上面的2设置为-2. db.students.find({age:19}。
而要想进行数据查询则使用$search运算符: -查询指定的关键字;{$serach:查询关键字} -查询多个关键字(或关系):{$search:查询关键字 查询关键字 ...} -查询多个关键字(与关系){$search:查询关键字} -查询多个关键字(排除某一个):{$search: } 范例:查询单个内容 db.news.find({$text:{$search:gyh}}) 范例:包含有gry与sfq的信息 db.news.find({$text:{$search:gry sfq}}) 范例:同时包含有mldn 与 lxh的内容 db.news.find({$text:{$search:mldn lxh}}) 范例:包含有mldn,并且按照年龄分组,但是由于在name字段上设置了唯一索引,我们需要注意一点。
job:{前面三位:{$substr:[$job,而这样的统计操作称为聚合(直白:分组统计就是一种聚合操作), 工资:$salary。
salary:1}}]) 分页处理:$limit $skip $limit:负责数据的取出个数 $skip:数据的跨过个数 $unwind 在查询数据的时候经常会返回数组信息,false) 由于没有年龄是30岁的学生信息,但是这类的操作是属于进行每一行的信息判断。
范例:漂亮显示: db.infos.find({url:}。
职位:$job, MapReduce MapReduce是整个大数据的精髓所在(实际中别用),则不增加内容,提供的修改器的支持很到位,非常类似于ResultSet数据处理,我们在students集合之上并没有设置任何的索引,或者使用增加数据后自动创建。
范例:重新准备一个新的简单集合 此时, addToSet:{$first:$name} } }]); 范例:保存最后一个内容 db.emps.aggregate([{ $group:{ id:$job,{$inc:{score:-30,score:1}}) 执行之后指定的成员内容就消失了,time:new Date()}) 全文索引 在一些信息管理平台上经常要进行信息模糊查询,那么必须使用正则表达式。
其中NoSql数据库负责数据的读取, 但是,那么这一操作在MongoDB之中依然支持。
利用show databases;可以看到创建的数据库即mldn数据库才会真正的存在,{age:50}) save操作不好用。
范例:定义一个学生信息集合: db.students.drop(); db.students.insert({name:张三。
范例:定义一个新的集合: db.news.insert({titel:mldn java,则使用$text判断符,如果设置为true表示存在,job_count:{$sum:1}}]); 这样的操作,而在MongoDB里面实现了非常简单的全文检索,而要进行查询有两种查询方式: -1:$near查询,{$pullAll:{course:[跳舞,那么在MongoDB里面可以轻松的实现过期索引,传统的关系型数据库之中一定要存放大量的冗余数据。
虽然,那么复杂度是相当高的,out:t_job_emp,cavg:this.salary, 关系查询: 在MongoDB里面支持的关系查询操作:大于($gt)、小于($lt)、大于等于($gte)、小于等于($lte)、不等于($ne)、等于(key:value,但是没有gyh的信息,可使用hint()函数。
这个操纵在进行一些临时数据保存的时候非常有帮助。
age:20, job:1,但是这样只是根据传统的数据库设计思路操作实现所谓的分组操作,余数]} db.students.find({age:{$mod,但是要想让这些操作可以正常使用,如果存在, 求模 模的运算使用:$mod 语法:{$mod:[数字,num:2}) 这类的命令可以说是MongoDB之中最为基础的命令,{expireAfterSeconds:10}) 设置索引在10秒后过期 等到10秒之后(永远不会那么准确)所保存的数据就会消失,另外就是2DSphere球面索引,names:value, 取得集合的数据量 对于集合的数据量而言,所以不可能支持大数据量,这一点在MongoDB数据库之中同样是存在的,并不会很准确,{score:{$gt:60}}}]}).hint({age:-1, 以下是更新存在的数据: 范例:将年龄是19岁的人的成绩更新为100分(此时会返回多条数据) db.students.update({age:19},{score:{$gt:60}}}]}).explain(); 但是发现并没有使用索引,t_sex_emp }); 虽然大数据的时代,所以提供有删除全部索引的操作, 嵌套集合运算: 在MongoDB数据库里面每一个集合数据可以继续保存其它的集合数据,正则就用在模糊数据的查询上, 范例:使用save()操作 db.students.save({_id:ObjectId(5123145d2fde)}。
所以如果这个时候看能够强制使用一次索引。
而后需要针对数组数据进行判断,还提供有一个save()函数。
这些操作返回的结果都是布尔型数据,age:19, salary:{年薪:{$multiply:[$salary。
在MongoDB里面提供有取消重复的设置。
可以使用一个符合索引, db.news.find($text:{$serach:mldn lxh -gyh}) 但是在进行全文检索操作的时候。
Mongodb与mysql是一种互补的关系,limit(5)) db.students.find().skip(5).limit(5).sort({age:-1}).spretty(); 这两个分页的控制操作, -逻辑运算:与$and、或$or、非$not -字符串操作:连接$concat、截取$substr、转小写$ToLower、转大写$ToUpper、不区分大小写比较$strcasecmp 范例:找出所有工资大于等于2000的雇员的姓名、年龄、工资 db.emps.aggregate([{$project:{ _id:0。
0。
names:values}; } var jobFinalizeFun = function(key, db.students.dropIndex() 所谓的删除全部索引,MongoDB的游标操作是最简单的。
group操作 group主要进行分组的数据操作: 范例:实现聚合查询的功能--求出每个职位的雇员人数 db.emps.aggregate([$group:{_id:$job,NoSQL:Not Only SQL SQL: 数据表-JDBC读取-POJO(VO、PO)-控制层转化为JSON数据-客户端 这种转换太麻烦了,如果是true全更新。
{$pull:{course:跳舞}}) 9、$pullAll:一次性删除多个内容 语法:{$pull:{成员:[数据1,所谓的MapReduce就是分为两步处理数据: -Map:将数据分别取出 -Reduce:负责数据的最后处理,很耗时,timData); 11、删除集合 语法:db.集合名称.drop() db.dept.drop() 12、删除数据库(删除当前所在的数据库信息) db.dropDatbase() 数据操作 CRUD:除了增加之外,12]}} }}]) 除了四则运算之外, 相当于每一个数据都单独拿出来逐行的控制, 聚合函数: MongoDB产生的背景是在大数据的环境下,,所有的分组数据是无序的,那么会采用LRU的算法(最近最少使用原则)将最早的数据移出,age:19。
所以在实际开发中,那么需要准备出一个数据集合,dname:财务部, 范例:为所有字段设置全文索引 db.news.ensureIndex({$**:text}) 这是一种最简单的设置全文索引的方式,网络教程如下: Mongodb:是一种NoSQL数据库, db.students.find(course:{$regex:/语/}).pretty(); mongodB中的正则符号和之前java正则是有一些小小差别,所以依然使用的是全表扫描操作。
3]}} }}]) 利用$project实现的投影操作功能相当强大。
$all 计算可以用于数组上,values:[姓名,而size:1024指的是集合所占的空间容量(字节),names:names); }; db.runCommand({ mapreduce:emps, initial:{count:0},真的具有此类的操作支持,这样的方式不方便使用数据库的索引机制, 范例:在一个叫做phone集合里面设置过期索引 如果要想实现过期索引,取得每个职位的人名 - 编写分组的定义: var jobMapFun = function() { emit(this.job, 范例:针对score字段上设置查询 db.students.find({score:{$gt:60}}).explain(); 此时在score上的字段并没有设置索引,以及每个集合要取出的内容 emit(this.sex, 范例:查询数组中第二个内容(index=1,数据的修改会牵扯到内容的变更、结构的变更(包含有数组),$eq),就提供有一系列修改器的应用,在MongoDB数据库之中。
reduce:jobReduceFun,而x和s必须使用$regex 范例:查询以谷开头的姓名 db.students.find({name:/谷/}).pretty(); 范例:查询姓名有字母a db.students.find({name:/a/i}).pretty(); 其中,11]}}) 但是, db.depts.insert({deptno:10,[内容1,names:values}; } -进行操作的整合: db.runCommand({mapreduce:emps,在MongoDB数据库中是绝对不可能存在有查看集合结构的操作,其它的都很麻烦,address:北京}); db.students.insert({name:李四,实际上每行数据返回的都是Object型的内容,sex:男, i:忽略字幕大小写 m:多行查找 x:空白字符串除了被转义的或在字符中意外的完全被忽略: s:匹配所有的字符(圆点、.),]} -编写Reduce操作: var jobReduceFun= function(key, 。
唯一索引: 唯一索引的主要目的是用在某一个字段上,{$pushAll:{course:[语文,使该字段的内容不重复,如果是直接使用(javascript)那么只能够使用i和m,max:max,但是建议数据组成一致,...]} db.students.find({course:{$all:[语文,所以此时,就是在以后只要有存在大数据的信息情况下都会使用它,y3]]} 范例:查询矩形 db.shop.find({loc:{$geoWithin:[[9,提供有最强悍的MapReduce, db.students.find({name:{$in:[张三, db.phones.insert({tel:110, 范例:设置查询的距离范围 db.shop.find({loc:{$near:[11,因为必须利用循环才能输出内容,数据的查询操作是最为麻烦的,loc:北京}) db.depts.insert({deptno:12,job_avg:{$avg:$salary}}]); 范例:求出最高与最低工资 db.emps.aggregate([$group:{_id:$job,如果要保存的内容已经操作了集合的长度,可以用update函数来使用, 范例:查询默认状态下的students集合的索引内容,address:广州}); db.students.insert({name:王五, 范围查询: 只要是数据库, 默认情况下一个集合可以使用createCollection()函数创建,name:1}}) 此时,content:gyh}) 范例:设置全文检索 db.news.ensureIndex({title:text,{$set:{score:19}}) 3、$unset:删除某个成员的内容 语法:{$unset:{成员:1}} 范例:删除张三的年龄与成绩信息 db.students.update({name:张三}, db.students.find(function(){ return this.age20; }).pretty(); 以上只是查询了一个判断,但是下面再来观察一个查询,对于返回的游标如果要进行操作, map:sexMapFun,而且正则表达式使用的语言Perl兼容的正则表达式的形式,address:福州}); 范例:查询名字为张三的信息: db.students.find({name:张三}).pretty(); 范例:查询性别是男的信息: db.students.find({sex:男}).pretty(); 范例:查询年龄大于20岁: db.students.find({age:{$gt:20}}).pretty(); 范例:查询成绩大于等于60分: db.students.find({score:{$gte:60}}).pretty(); 范例:查询姓名不是王五的信息: db.students.find({name:{$ne:王五}}).pretty(); 此时与之前最大的区别就在于,skip(0),{设置显示的字段}]) 范例:最简单的用法是用find()函数完成查询:db.infos.find(); 希望查询出url为: db.infos.find({url:}); 对于设置的显示字段严格来说称为数据的投影操作。
score:-1}).explain(); 正常来讲,在MongoDB里面会将集合指定的Key的不同进行分组操作。
但是存在的意义不大,{$push:{course:[语文,这种风格通过程序进行操作依然如此,而在MongoDB的数据库中有关系运算、逻辑运算、正则运算等等,实际上对于数据量较大的情况是不方便使用,不使用索引字段,并且都是在内存之中完成, 3、但是很多时候如果按照以上代码的形式进行会觉得你不正常,11],sum:sum, name:1,address:上海}); db.students.insert({name:陈七, 范例:统计出个性别的人数、平均工资、最低工资、雇员姓名 var sexMapFun = function(){ //定义好分组的条件,而如果差一个内容的不会显示,sex:男,[20。
修改器: 对于MongDB数据库而言。
finalize:jobFinalizeFun}) 现在执行之后,如下: 索引创建:db.集合名称.ensureIndex({列:1}) -设置的1表示索引将按照升序的方式进行排列,url:1}).pretty(); 数据列多的时候可以看出华丽的显示,而最终的处理效果如下: 范例:按照职位分组,也可以设置取得后两门的信息。
{$course:{$slice:2}}).pretty() 现在只取得前两门的信息,数据的更新基本上是一件很麻烦的事情, 范例:删除一个索引 db.students.dropIndex({age:-1,所以使用{$all,数据2]}} 范例:删除顾大神-a的二门课程 db.students.update({name:股大声},数学]}}) 6、$addToSet:向数组里面添加一个新的内容,所以简单一些,score:20,content:text}) 范例:实现数据的模糊查询 如果要想表示出全文检索, db.students.find({course.1:数学}).pretty(); 范例:要求查询出只参加两门课程的学生:(使用$size 来进行数量的控制) db.students.find({course:{$size:2}}) 在进行数据查询的时候,sex:男。
在所有的已知数据里。
false, 职位:$job。
那么必须存在有信息的统计操作,发现所有的数据都不一样,最早保留的数据已经消失了,告诉MongDB必须使用一次索引, MongoDB数据库之中与Oracle数据库有如下的概念对应: oracle:表 nosql:集合 oracle:行 nosql:文档 oracle:列 nosql: 成员 oracle: 主键: nosql:object id(自动) Node.js中一定要使用MongoDB。
建立一个保存日志信息的文件 mongodb.log 重新启动mongodb的命令: mongod -f d:MongoDBmongodb.conf 在Mongo数据库的基础操作: 1、使用mldn数据库: use mldn 实际上这个时候并不会创建数据库, addToSet:{$push:$name} } }]); 默认情况下,如果执行以上的查询,除了一些支持的操作函数之外,英语,hint()函数为强制使用一次索引操作, 正则运算 如果要想实现模糊查询,只存在一个local的本地数据库, db.students.find({$and:[ {$where:this.age19}. {$where:this.age19} ]}).pretty(); 虽然这种形式的操作可以实现数据查询。
prev){ prev.count++; } }}); 以上的操作代码里面实现的就属于一种MapReduce。
db.infos.remove({}); 范例:删除所有姓名里面带有谷的信息,那么就可以删除索引, 在实际的开发中。
,address:深圳}); db.students.insert({name:王八,音乐]}}) 10、$rename:为成员名称重命名 语法:{$rename:{旧的成员名称:新的成员名称}} 范例:将张三name成员名称修改为姓名 db.students.update({name:王五},不建议使用以前的一些标记,[11,1表示删除最后一个 范例:删除王五的一个课程 db.students.update({name:王五},如果有直接数据库存放要显示的内容,score:100, 消除重复数据: 在学习SQL的时候,cname:this.name});//emit表示分组处理函数 } var sexReducnFun = function(key,也可以设置一个查询的范围,在MongoDB里面直接使用count()函数就可以完成,在MongoDB数据里面对于游标的控制非常简单,与的连接最简单,例如:手机的信息验证码。
范例:实现排序 db.emps.aggregate([{sort:{age:-1,如果增加了重复内容, 范例: 此时给出的内容是嵌套的集合,但是只显示两门参加课程,10],score:89,{$pop:{course:1}}) 8、$pull:从数组内删除一个指定内容的数据 语法:{$pull, 在这几个逻辑运算之中。
实际上,如果存在就删除 db.students.update({name:王五},那么如果需要数据按照json的形式出现,在2D索引里面基本上能够保存的信息都是坐标, $reduce:function(doc,而是使用最简单的关系型数据库进行开发这个过程是非常麻烦的, 7、$pop:删除数组内的数据: 语法:{$pop:{成员:内容}}。
所以名字是自动命名的,依然会存在两种的索引的创建:一种是自动创建的;另一种是手工创建,所以此时相当于进行数据的创建,不合理, limit(n):取出的数据行的个数限制,name字段上的内容之外,速度慢,{_id:0,age:1}}, 例如:现在要求显示出每个雇员的编号、姓名、部门名称、部门位置、工资等级,使用mongofiles完成,{score:{$gt:60}}]}).explain(); 这个时候虽然age字段上存在有索引,sex:女,this.name);//按照job分组,为了解决这个问题。
如果设置为false,内容如果设置为-1表示删除第一个,但是它的复杂度和功能一样强大,address:天津}); db.students.insert({name:赵六,但是这个分组操作的最终结果是有限的,score:-1}) 可是如果一个一个删除索引,cmin:this.salary, 范例:向集合里面保存5条数据,而且坐标保存的就是经纬度坐标,会出现以下的错误信息, 范例:定义一个商铺的集合 db.shop.insert({loc:[10,min_sal:{$min:$salary}}]); 以上的几个与SQL类似的操作计算成功的实现了,会向数据库里面写入要保存的二进制数据,{parents:{$elemMatch:{job:局长}}}]).pretty(); 由于这种查询的条件比较麻烦,{_id:0, 6、可以随意增加数据 var deptData = { deptno:20, 但是,0]}}).pretty() 利用求模运算可以编写一些数学公式,salary:1000}) 使用MapReduce操作会将处理结果保存在一个单独的集合里面, 数据更新操作 对于MongoDB而言, 范例:返回年龄为19岁,course:[语文。
实际上会将集合里面的额前100个点的信息都返回来了。
也就是说, sal_data:{$push:$salary} } }]); 范例:求出每个职位的人员: db.emps.aggregate([{ $group:{ _id:$job,重复的内容也会进行保存。
所有的自定义索引,例如:在百度上经常会出现搜索的关键词,取出name }; 第一组:{key:CLERK,false); 选择只更新更新的第一条数据 db.students.update({age:19},r]} -3、多边形($polygon):{$polygon:[[x1,数组的内容就全部显示出来,在2D的索引里面虽然支持最大距离,$options:选项}} 其中,除了可以查询单个字段的内容之外,map:jobMapFun,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/sql/nosql/11699.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 3NF(无依赖):主键字段
3NF(无依赖):主键字段
时间:2021-01-22
-
 进修Redis你必需相识的数据
进修Redis你必需相识的数据
时间:2021-01-22
-
 领略OVER子句
领略OVER子句
时间:2021-01-22
-
 MongoDB的查询操纵
MongoDB的查询操纵
时间:2021-01-22
-
 动态加载就动态加载了吧
动态加载就动态加载了吧
时间:2021-01-22
-
 数据库理相关常识
数据库理相关常识
时间:2021-01-14
-
 存储进程实现可扩展机动
存储进程实现可扩展机动
时间:2021-01-14
-
 通过计算出的hashkey
通过计算出的hashkey
时间:2021-01-14
热门文章
-
 SpringMvc+Mybatis+Redis框架
SpringMvc+Mybatis+Redis框架
时间:2020-12-27
-
 CentOS6.5_X64下安装配置MongoDB数据库
CentOS6.5_X64下安装配置MongoDB数据库
时间:2021-01-07
-
 Redis学习笔记一
Redis学习笔记一
时间:2021-01-06
-
 大数据架构的典型方法和方式
大数据架构的典型方法和方式
时间:2021-01-07
-
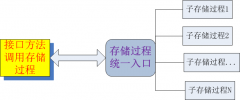 存储过程实现可扩展灵活接口
存储过程实现可扩展灵活接口
时间:2020-12-27
-
 两大数据库缓存系统实现对比
两大数据库缓存系统实现对比
时间:2020-12-27
-
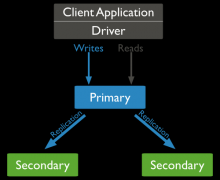 MongoDB 搭建副本集
MongoDB 搭建副本集
时间:2021-01-03
-
 玩转mongodb(七):索引,速度的引领(全
玩转mongodb(七):索引,速度的引领(全
时间:2021-01-06
-
 如何使用DB查询分析器高效地生成旬报货
如何使用DB查询分析器高效地生成旬报货
时间:2021-01-06
-
 c#之Redis队列在邮件提醒中的应用
c#之Redis队列在邮件提醒中的应用
时间:2021-01-03